GitHubが作った謎のAPI?BOT? / Meet the Noopsで面白くてくだらない機能を作ってみよう!

なんだこの謎のサイトは・・・!GitHubが先日謎のサイトとリポジトリを作成していたのをご存知でしょうか?
最初は全貌がよくわかっていなかったのですが、どうやらお題やAPIが用意されていてそれを使って面白い機能を作って公開するというプログラミングチャレンジが行われているようです。
紹介されているブログはこちら。
お題は毎週ごとに5問ずつ追加されるようで、現在はLevel2までのAPIを用意しています。
どんなAPIやお題があるの?
- ドラムパターンを出力するAPI
- ベクトルを出力するAPI

- 上下左右の方向とスピードを出力するAPI

迷路を出力するAPI noops-challenge.github.io
ポリゴンを出力するAPI

他にもあるので見てみると面白いですよ!
自分も作ってみた
ブログで紹介する以上、私も何か面白いものを作らないといけませんね!
Hexbotにチャレンジ
私がチャレンジしたBOTはHexbotというAPIにアクセスするとランダムな16進数のカラーコードを返すBOTを使用することにしました。
noopschallenge.com
APIの内容
HexbotのAPIの内容について解説を行います。
なにもパラメーターを指定せずにGETするとランダムに1つのカラーコードが返されます。
https://api.noopschallenge.com/hexbot
GET /hexbot
{ "colors": [ {"value": "#52a351"} ] }
countで数値を渡すと1000までの範囲でカラーコードを返します。
GET /hexbot?count=5
{ "colors": [ {"value": "#EF7FED"}, {"value": "#5F47C2"}, {"value": "#D5FF9F"}, {"value": "#62B217"}, {"value": "#DD36D9"} ] }
widthとheightを与えるとその数値の範囲内でxとy座標を返します。
GET /hexbot?count=5&width=1000&height=1000
{ "colors": [ { "value": "#4E3E97", "coordinates": { "x": 367, "y": 419 } }, { "value": "#D6381F", "coordinates": { "x": 180, "y": 41 } }, { "value": "#F82971", "coordinates": { "x": 145, "y": 495 } }, { "value": "#D680CF", "coordinates": { "x": 493, "y": 148 } }, { "value": "#F92C20", "coordinates": { "x": 152, "y": 380 } } ] }
作成した機能について
さて私はChrome拡張機能として2つ作ってみました!GitHubに公開しております!
①カラーポインター
マウスの動きに合わせてカラフルなポインターが表示されます。

②カラフルモザイク
Webページ上で隠したい箇所にカラフルなモザイクをかけます。

他の人の活用アイデア
個人的に面白いアイデアだな!と思ったのがこちら!
時間(hh:mm:ss)を16進数(#hhmmss)に見立てて毎秒ごとに画面の背景に描画しています。実用性は皆無なわけですが、こんな使い方もあるなと感心してしまいました。
まとめ
- GitHubのプログラミングチャレンジMeet the Noopsを紹介した
- 色々なAPIやそれの活用事例が掲載されていて自分が作ったものを投稿できる
- 課題をクリアするとGitHubのコミュニティフォーラム限定バッジがプレゼントされるらしい
この夏みなさんもチャレンジしてみてはいかがでしょうか!?
【機械学習】Google I/O・AWS Summit・WWDC2019年総まとめ!共通点と違いは?
ここ数ヶ月Google/AWS/Appleの開発者向けイベントが開催されました。私も国内イベントに参加や視聴をしてきました。
そこから各社の共通点や注力してるポイントが見えてきましたのでまとめていきたいと思います。
機械学習 / ディープラーニングに限定してまとめております。
エッジデバイス / オンデバイスで機械学習
エッジデバイス(クラウドを利用しない)で動く機械学習を強化してきています。GoogleとAWSの取り組みをご紹介します。
これまでGoogleはクラウド活用した機械学習が主流でした。エッジデバイス側で機械学習を行うというのは容量やCPU使用率の問題で動作が非常に遅く使いづらいものでしたが、技術の進化によりエッジデバイス側で機械学習を行うという事例が増えてきています。
アプリのみで動作するML Kit(後述) / アプリやラズベリーパイで動作するTensorFlow Lite / Webブラウザ上で動作するTensorFlow.jsがあります。
TensorFlow Lite
TensorFlow LiteはTensorFlowの学習モデルをモバイルアプリ・ラズベリーパイ・マイコンなどで動作させる事ができるフレームワークです。 CPUではなくGPUを利用し、容量も一般の機械学習のモデルサイズの数百MBから1/4程度まで落とすことが可能です。
【事例】 CareOS
ラズベリーパイ上で顔の認識やセグメンテーションをリアルタイムで行なっています。メガネをかけたり髪の毛の色を変えたりする事例です。
TensorFlow.js
Webブラウザで動作する機械学習です。クラウドにアクセスすることなくJavascriptでTensorFlowを動かすことができます。
【事例】BodyPix(人間の画像をセグメンテーション)

AWS
AWSもエッジデバイスによる機械学習に力を入れてきています。
SageMaker Neo

Amazon SageMaker Neo は、精度を損なうことなく、10 分の 1 以下のメモリ使用量で最大 2 倍の速度で実行するようにモデルを最適化します。最初に、MXNet、TensorFlow、PyTorch や XGBoost を使って機械学習モデルを構築し、Amazon SageMaker を使ってトレーニングします。次に、ターゲットハードウェアプラットフォームを選択します。ワンクリックで、Amazon SageMaker Neo はトレーニング済みモデルを実行できるようにコンパイルします。
こちらもTensorFlow Liteと同じでメモリ使用量を下げて実行速度を早くしたエッジデバイス向け機械学習を提供しています。
特徴としてTensorFlowだけでなくPyTorch、MXNetなどディープラーニングのライブラリーが限定されないところが強みです。
機械学習をより簡単に実装する
機械学習を深く理解していなくても画像認識などが簡単に実装できる機能や、機械学習のワークフローを簡単にする仕組みが提供されております。
ML Kit
モバイルアプリ上で動く機械学習の実行環境です。モバイルアプリで機械学習機能を開発する前提で、やりたいことがML Kitで実現できる内容であればTenforFlow Liteを使うより簡単に実装が可能です。
2019年に新しく追加されたML Kitの機能
- ML Kit On Device Translation
オフラインで動く翻訳機能で、Google翻訳と同じモデルを使用
- Object Detection & Tracking API
画像の中でオブジェクトを検出してくれる機能
【事例1】 LIFULL HOME'sアプリでの外国人向け多言語翻訳機能
【事例2】 以前、ブログにてML KitのObject Detectionの記事を書きましたのでそちらもご覧ください。
AutoML Vision Edge
簡単にオリジナルの画像分類が実装できるML Kitの機能です。
- 識別したい写真を集めてFirebaseのコンソールにアップロード
- 写真の識別を行うモデルをAutoML Vision Edgeが自動的に作成してTensorFlow Liteの形に変換
- ML Kit経由でアプリに配布して画像分類
という簡単な作業のみでカスタムの画像分類が可能になります。
AWS
AWSは機械学習のワークフローを簡単にしたり自動化したりする部分にかなり注力している印象です。
Amazon SageMaker Ground Truth

Ground Truth を使用すると、ラベル付きデータセットを作成できる機械学習とともに、選択したベンダー会社、または社内のプライベートワークフォースのいずれかの
Amazon Mechanical Turkのワーカーを使うことができます。
今まで機械学習の画像認識分野などでデータセットを用意する際に大変だったのが、データのラベル付けです。Amazon SageMaker Ground Truthはデータのラベル付けのワークフローを自動化します。
信頼性スコアがしきい値を下回る場合、データが人に送信され、人がラベルを付けます。人がラベルを付けたデータの一部は、ラベル付けモデルの新しいトレーニングデータセットを生成するために使用され、モデルは精度を向上させるために自動的に再トレーニングされます。
詳細は以下ご覧ください。
Apple
2018年から簡単に機械学習を実装できる環境を提供し始めました。今年はさらに強化されております。
Core ML
公式で用意している学習モデルが増えました。これらはモデルを作成する必要がなく利用が可能です。
- 深度推定(単一画像からデプスの推定が可能)
- 画像のセグメンテーション
- オブジェクト検出
Create ML
ドラッグ&ドロップで機械学習のモデル作成が可能です。 物体検出、音・行動の分類など実装できる機能の種類が増えました。

Turi Create
PythonでCore MLモデルを作ることができるAppleのライブラリです。
One Shot Object Detectionという機能が追加されました。今までモデル作成にあたりたくさんの画像が必要でしたが、1枚の画像で物体検出が可能になります。
私もTuri Createを活用した画風変換のブログ記事を出しております。よければご覧ください。
AIサービス比較表
AIサービス群の比較をおこないます。単純な比較は難しいので詳細については別途お調べください。
| 機能 | AWS | Apple | |
|---|---|---|---|
| 翻訳 | Cloud Translation API/ ML Kit On Device Transition | Amazon Translate | - |
| 音声認識 | Cloud Speech-to-Text | Amazon Transcribe | Speech Framework |
| 自然言語処理 | Cloud Natural Language API | Amazon Comprehend | Natural Language framework |
| 音声合成 | Cloud Text-to-Speech | Amazon Polly | AVSpeechSynthesizer |
| レコメンデーション | Recommendations AI | Amazon Personalize | MLRecommender |
| 時系列分析 | Cloud Inference API | Amazon Forecast | - |
| 画像分析 | Cloud Vision API | Amazon Rekognition | - |
| 動画分析 | Cloud Video Intelligence API | Amazon Rekognition Video | - |
| OCR | Cloud Vision API(OCR) | Amazon Textract | VNRecognizeTextRequest |
| 顔検出 | Cloud Vision API / Detect Faces with ML Kit | Amazon Rekognition | VNDetectFaceLandmarksRequest |
各社の特徴
各社の強みや特徴についてまとめたいと思います。個人の見解も含まれている部分もありますのでご了承ください。
マルチデバイス/クロスプラットフォーム
上記にも記載した通りWebブラウザでも動くしiOS/Androidアプリやラズベリーパイ/マイコンでも動かせる仕組みを公式でサポートしております。クラウドのAIサービスや無料のGPU学習環境のColaboratoryなどの提供もしており、Googleのサービスだけである程度の機械学習は実現できてしまうくらい網羅している印象です。
AIを普及させるための取り組み
GoogleはAIを普及させるために資料やデータセットを積極的に公開しています。
People + AI Guidebook
AIがユーザーにとって使いやすいサービスとなるためにどのような設計にすればいいのかを紹介している公式の資料になります。
Machine Learning Fairness
機械学習を行う際に集めたデータセットの内容に偏りがでると差別や不公平な学習モデルが生まれてしまいます。 国籍や性別に影響されないデータセットを用意するためにGoogleがデータセットを公開しています。
今まで欧米のデータセットが多かったのですがこちらのデータはインド・アフリカ・中近東を中心に集められているので偏りが少ない機械学習が可能になるそうです。
AWS
ビジネスシーンに特化
これらはAmazonのリテールビジネスの予測に使われていたレコメンデーションや需要予測の機能をベースに作られている技術とのことです。Amazonはクラウドベンダーでもありながら小売業でもあるため、かなりの期待が寄せられます。
継続的な機械学習ワークフローの実現
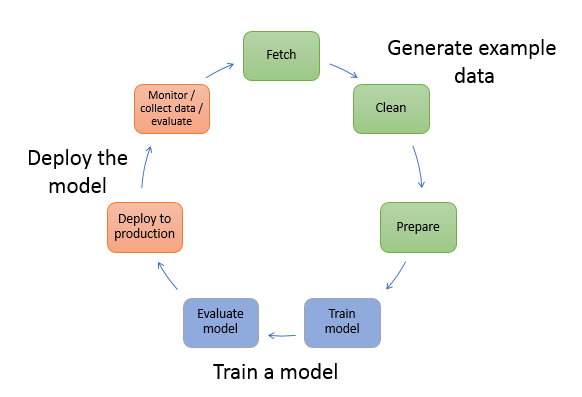
Amazon SageMaker Ground TruthやAWS Step Functions 、Amazon ECRなどAWSのサービスをフル活用し「データ収集→クリーニング→データ変換ラベル付け→トレーニング→モデル評価→本番にデプロイ→推論監視→データ収集」といったワークフローを楽にして継続的にチューニングする仕組みを導入しやすいです。
Apple
AR体験を強化
- People Occlusion(人を認識してARオブジェクトを隠す機能)
- Motion Capture(体の動きを認識)
iOS13で搭載されるARKit3では、上記の機能でApple独自のMachine Learningが活用されています。

運動・健康促進
Apple Watchセンサーを利用してどんな動きをしているかを予測することができます。これを利用して日々の運動の可視化など健康促進に繋げることができますね。個人的には百式観音の動きをマスターできるようになりたいです。

ARもセンサーもOSからデバイスまでアップルが自社で管理しているからできることであり、強みなのではないかと考えられます。
まとめ
- Google / AWS / Appleは機械学習をより簡単にし誰でも扱えるような仕組みを提供し始めている
- デバイスの進化によりエッジ側で機械学習の推論する事例が増えてきており各社も推進している
- 各社それぞれに強みがあり独自のノウハウを最大限に生かした機械学習を提供している
- お互いの仕組みを要件に応じて組み合わせたりするのがいいかもしれない
参考にしたサイトや資料
WWDC
AWS Summit
Google I/O
【ML & AI】Google I/O Extended: Recap Live Japan 2019 #RecapLiveJP
【Firebase & ML Kit】Google I/O Extended: Recap Live Japan 2019 #RecapLiveJP
Googleが開発した「Game Builder」は3Dゲーム開発をしながらプログラミングを覚えられる

先日Googleがコーディング不要でゲーム開発できるGame Builderをブログで発表し話題になっていた。リリース自体は2018年に行なっていて、今回いくつかの機能が大幅にアップデートされている。
今回はGame Builderを試してどれだけ簡単に3Dゲームが開発できるかを紹介したい。
どんなユーザーにおすすめか
このゲームをオススメしたいユーザーは「新しくプログラミングを学びたい人」である。ゲーム内にでてくるLOGICはコードを打たないプログラミングであり、楽しんでプログラミングの考え方を学べるのではないかと感じた。
一方で「簡単にゲームが開発できて他のゲーム開発エンジンが危ない」ということは現在の段階ではまったく感じられない。あくまで「ゲームを作るゲーム」である。作ったゲームを公開して誰かに遊んでもらうというような機能もなかった。
ちなみに裏ではUnityを使っている。

Game Builderの特徴について
公式ブログでは5つの特徴が紹介されている。これらの要素が組み合わさり簡単にゲーム構築が可能になる。
Built for gamers
このゲームは「ゲームを製作するゲーム」である。マインクラフトに近い形でオブジェクトや地形を作ることができ、さらにプログラムを組み込むことができる。ゲーマーが楽しんで作れる仕組みになっている。
Always-on multiplayer
複数のユーザーが同時にゲームを開発できる。
No code required
カードをドラッグ&ドロップするだけでロジック(プログラム)を構築できる。パラメーターなどはカードの値をいじることで調整する。
Real-time JavaScript
上記のカードに自分で新しい要素を作る場合、JavaScriptを使って開発ができる。
Thousands of 3D models
Google Polyにある数千の3Dモデルを使ってゲームに取り込むことができる。
環境構築
開発を行う前に必要なソフトウェアなどのインストールを行う必要がある。
ダウンロードリンク
Game Builderのダウンロードはこちらから。
なおGame Builderの利用にはSTEAMというアプリのインストールが必要になる。
アカウント登録
STEAMのアカウントを取得していない人は登録が必要である。
チュートリアルを試す
NEW PROJECTを選択するといくつかのゲームタイプが表示される。ゲームの操作方法を学ぶためにも「Tutorial」を試す。

操作方法
チュートリアルを試しながら「ゲームをプレイするときの操作方法」と「ゲームを作るときの操作方法」を学ぶことができる。

【プレイ時の操作方法】
- 十字キーあるいはキーボードの「AWSD」で移動、シフト押しながらだと走る
- スペースでジャンプ
- Vで視点の変換、Eで武器などを持つ
- マウスの位置で体の向きを変更する
【ゲーム開発時の操作方法】
Tabあるいは画面上部にあるBUILDを選択するとゲーム開発モードになる

- CREATE | 3Dオブジェクトを作成する
- MOVE | 作成した3Dオブジェクトを移動する(terrainは除く)
- ROTATE | オブジェクトを回転する
- SCALE | オブジェクトの拡大縮小をする
- TERRAIN | オブジェクト以外の地形を作成する(壁や地面など)
- TEXT | 画面上に表示するテキストを作成する
- LOGIC | オブジェクトにルールを付与する
- EDIT | オブジェクトに情報や属性を付与する
LOGICについて
ゲーム開発の中で一番重要になってくるのがLOGICである。ここにカード形式でアクションや状態遷移などのプログラムを行なっていく。
MOVEMENT

オブジェクトの動きを指定でき、複数の動きをカードで重ね合わせることも可能。上記のスクリーンショットの場合は、オブジェクト自体が回転しながらランダムに動き回るプログラムになっている。
IF THEN

もし〇〇だったら××するというプログラムができる。こちらのスクリーンショットの場合は、オブジェクトがプレイヤーに衝突したらオブジェクトが赤くなる。
HEALTH

主にプレイヤーのダメージの管理に利用する。上記の場合はダメージを受けたら赤くして画面をシェイクしている。また死んだ時は最終時のチェックポイントに戻り体力は回復している状態になる。
GRABBABLE ITEM

武器に対してのプログラムができる。上記の場合はビームがでるようになっている。
PLAYER CONTROLS

操作するプレイヤーの動きの管理ができる。この場合は歩く・ジャンプ・武器をもつことができる。
また歩くスピードやジャンプする高さを設定で変えることができる。

CUSTOM
既存のカードに無いアクションなどを行いたい場合は、JavaScriptでプログラムを行える。作成したコードはカードの1つとして管理して使うことができる。

GAME LIBRARYについて
Tutorialを一通り試した後はいくつかのサンプルを試すことができる。
FPS
FPSゲームのサンプルを試すことができる。
Platformer
アクションゲームのようなオブジェクトの動きなどを参考にできる
Card Demos
いろんなオブジェクトのLOGICの事例を見れるのでGame Builder内でのゲーム開発の参考になる。
ゲーム開発の流れ
上記に紹介した機能を組み合わせると「Game Builder」では以下のような開発の流れになるかと思われる。
- CREATEでオブジェクトを配置
- TERRAINで地形を配置
- LOGICでアクションやプログラムを加える
- 3に必要なアクションが無い場合はJavaScriptでカスタムカードを作成
- 色/向き/大きさ/位置を変更する場合はEDIT/ROTATE/SCALE/MOVEを使用する
1~3の組み合わせでゼルダの伝説やFPSのようなゲームは簡単に開発ができる。簡単なゲームではほぼコードを書く必要がなく、ただIF THENのようなプログラム的な発想を学ぶことができ、複雑なことがしたくなったらコードを書くことになるためステップアップしながら学ぶことができる。
最後に
- 3Dゲーム開発が簡単にできるGame Builderを試した
- プログラミングの発想を学ぶのに最適のゲームである
- LOGICというものを使用してゲーム内でプログラムを組んでいく
- 簡単に高クオリティなゲーム開発をできるようになるにはまだ時間がかかる